Lab 4: Estimation
Introduction
Statistical inference is the process of using data from a sample to draw conclusions about a larger population. Since it’s often impractical to collect data from an entire population, statistical inference allows researchers, practitioners, and policymakers to make informed decisions based on limited information. This is particularly important in public health, where every decision we make — in guiding interventions, allocating resources, or addressing the health needs of populations — should be grounded in evidence.
Estimation is one of the two main types of statistical inference — the other being hypothesis testing, which we will cover in the coming weeks. Estimation focuses on determining the value of a population parameter — such as a mean or proportion — using sample data. For example, we might estimate the average cholesterol level in a population, the difference in smoking prevalence between two groups, or the prevalence of diabetes in a community.
Estimation involves two types of estimates — point estimates and interval estimates. A point estimate provides a single value as the “best guess” for a population parameter. For example, a sample mean provides a point estimate of the population mean. As we learned last week, when sampling from a population, many samples — and many values of the statistic of interest (e.g., mean, proportion) — are possible. So while point estimates are simple and easy to calculate, they do not convey the uncertainty inherent in using sample data.
In contrast, an interval estimate — which we’ll also refer to as a confidence interval — provides a range of values within which the population parameter is likely to fall. Interval estimates account for variability in the data and provide a measure of uncertainty, giving us more information than a point estimate alone. For example, instead of estimating the average cholesterol level as exactly 200 mg/dL (point estimate), a confidence interval might suggest the true population mean lies between 195 and 205 mg/dL with a specified level of confidence.
In Lab 4, we will apply estimation techniques for four types of population parameters often of interest in public health: (1) a single population mean; (2) the difference between two population means; (3) a single population proportion; (4) and the difference between two population proportions.
Objectives
After completing Lab 4, you will be able to:
- Apply statistical estimation to draw inferences about population parameters.
- Interpret confidence intervals and understand their role in quantifying uncertainty in public health research.
- Use R/RStudio to compute and interpret point and interval estimates for population means, proportions, and their differences.
Tasks
In Lab 4, we will continue working with the Framingham Heart Study teaching dataset. A key assumption we will make is that the baseline sample is representative of the adult population of the city of Framingham, MA.
When you are ready to start Lab 4:
- First create a new R Markdown file using the instructions on the
Assignment Guidelines page. Save this
.Rmdfile in a folder dedicated to Lab 4 materials. - Next, save the modified dataset you created in Lab 2 — called “frmgham2_p1_impute.csv” — in the same folder as your Lab 4 R Markdown file. This file will be located in the folder you used as your working directory in Lab 2.
- Finally, proceed to read through and carry out each of the tasks detailed below. As usual, you will begin by loading R packages, setting your working directory, and importing the dataset.
1. Install and load R packages
In Lab 4, we will use functions from a few new packages, so these will need to be installed before you proceed. Copy and paste the following into your Console (bottom-left window), the click Return/Enter, to install the new packages:
install.packages(c("ggplot2", "BSDA", "car"))After these packages have been installed, they will need to be loaded
with the library() function each time you start a new R
session:
# load packages
library(tidyverse)
library(ggplot2)
library(BSDA)
library(car) # only needed for Levene's test
library(stats)Note: Some students have had trouble installing/loading the “car” package in the past. If this happens to you, know that Lab 4 already contains alternative functions for certain tasks that do not require use of the “car” package. Please do let me know if you run into any issues.
2. Set your working directory
Set your working directory manually or using the setwd()
function:
setwd("YOUR FILE PATH HERE")3. Import the dataset into RStudio
Use the read.csv() function to bring in the modified
dataset you created in Lab 2. For this to work, the
“frmgham2_p1_impute.csv” file will need to be saved in the working
directory you specified in the above step.
4. Identify and modify variable types
In both Labs 1 and 2, we discussed the importance of identifying and modifying variable types as needed. This is to ensure variables are treated appropriately in our analyses and our final results are interpreted correctly. Variables that represent quantifiable characteristics (e.g., BMI) should be treated as numerical, while variables that represent categories should be treated as such (i.e., as categorical or factor variables). So, let’s start by checking variables types in our dataset:
## RANDID SEX AGE BMI TOTCHOL EDUC OBESE
## "integer" "integer" "integer" "numeric" "integer" "integer" "integer"Just as we did in Lab 2, we’ll need to modify the variable types for
sex assigned at birth, attained education, and obesity status. While
these variables take on numerical values in our dataset, these values do
not represent actual quantities — rather, they represent categories with
no inherent quantity. Remember that we also need to specify whether a
categorical or factor variable is ordered or unordered (i.e., ordinal or
nominal). Notice in the code chunks below that, for unordered
(i.e., nominal) categorical variables like sex assigned at birth and
obesity status, we specify ordered = FALSE, whereas, for
ordered (i.e., ordinal) categorical variables like attained
education, we specify ordered = TRUE.
# convert sex to unordered factor variable
data$SEX <- factor(data$SEX,
levels=c("1", "2"),
ordered=FALSE)# convert attained education to ordered factor variable
data$EDUC <- factor(data$EDUC,
levels=c("1", "2", "3", "4"),
ordered = TRUE)# convert obesity status to unordered factor variable
data$OBESE <- factor(data$OBESE,
levels=c("0", "1"),
ordered=FALSE)Now that we have prepared our dataset for analysis, suppose we want to use the Framingham Heart Study baseline sample to estimate characteristics of the adult population of the city of Framingham. In other words, we will use the baseline sample to draw inferences about our population of interest. In the following tasks, you will:
- Estimate the population mean of body mass index (BMI)
- Estimate the difference in mean BMI between male and female sex assigned at birth
- Estimate the population proportion of obesity (i.e., obesity prevalence)
- Estimate the difference in obesity prevalence between male and female sex assigned at birth
5. Estimate a population mean
Suppose you are interested in studying body mass index (BMI) and want
to start by estimating mean BMI of the adult population of the city of
Framingham. In this case, the population parameter of interest
is the population mean of BMI. Before we jump into estimation
techniques, let’s quickly summarize our dataset using the
summary() function and also visualize the distribution of
BMI with a histogram.
## RANDID SEX AGE BMI TOTCHOL
## Min. : 2448 1:1944 Min. :32.00 Min. :15.54 Min. :107.0
## 1st Qu.:2440336 2:2490 1st Qu.:42.00 1st Qu.:23.09 1st Qu.:206.0
## Median :4972848 Median :49.00 Median :25.46 Median :234.0
## Mean :4987278 Mean :49.93 Mean :25.85 Mean :236.9
## 3rd Qu.:7463577 3rd Qu.:57.00 3rd Qu.:28.06 3rd Qu.:263.0
## Max. :9999312 Max. :70.00 Max. :56.80 Max. :696.0
## EDUC OBESE
## 1:1935 0:3860
## 2:1281 1: 574
## 3: 716
## 4: 502
##
## 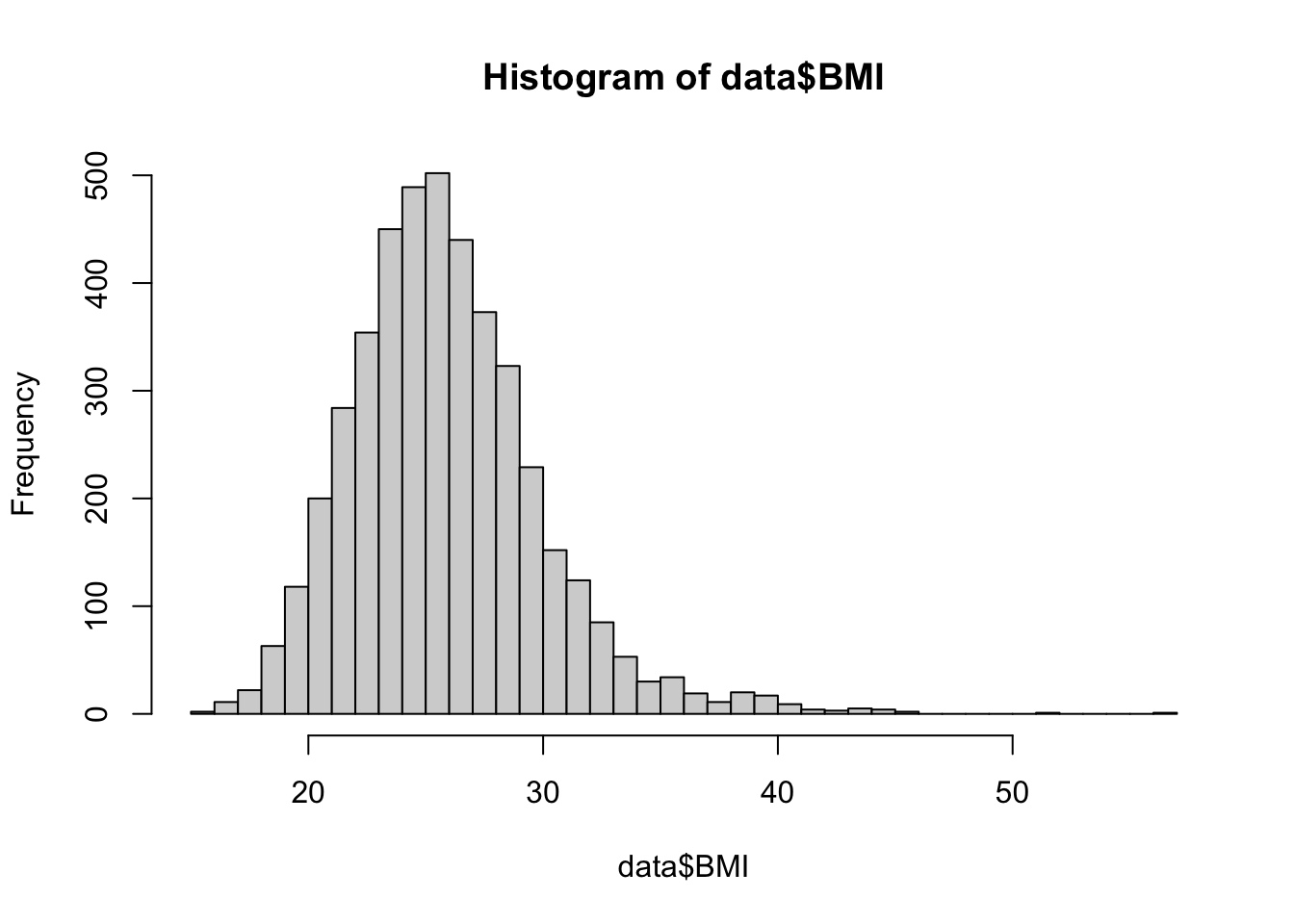
From the summary of our dataset, we can see the mean BMI in the sample is 25.85. This aligns with our view of the histogram for BMI, which shows the bulk of the distribution centered near this value. While we have this point estimate of the population parameter, an interval estimate (i.e., a confidence interval) will better capture the uncertainty in this measure.
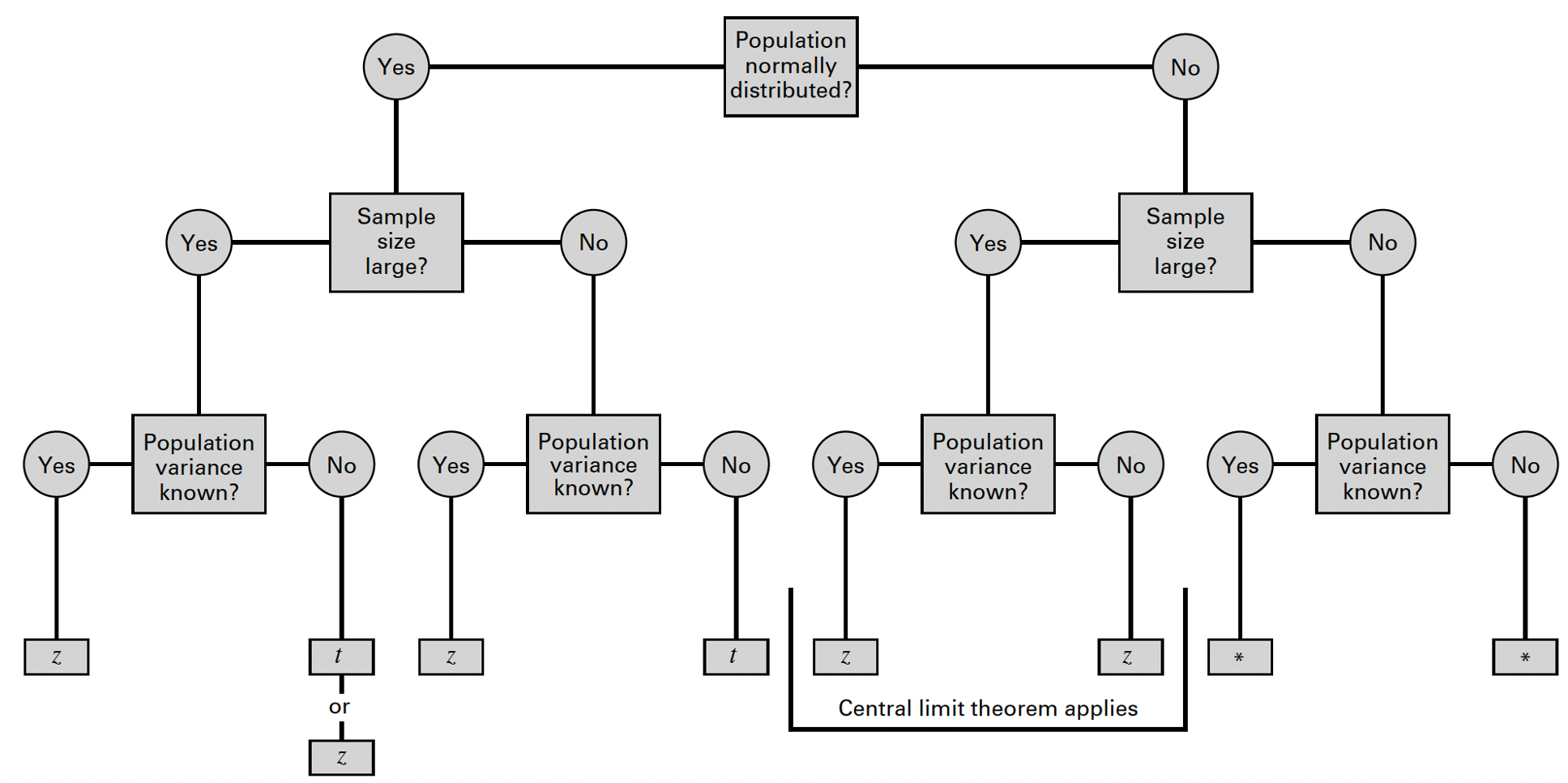
Recall from lecture that the method we use to generate an interval estimate of the population mean depends on three conditions:
- Whether the population is normally distributed;
- Whether the sample is small or large (≥30); and
- Whether the population variance is known or unknown.
These conditions determine the appropriate reference distribution, which is the theoretical probability distribution used as a benchmark to calculate estimates and assess uncertainty in statistical inference. It represents how a sample statistic, such as the sample mean or sample proportion, would behave if we repeatedly sampled from the same population. In the context of estimation, the reference distribution allows us to construct confidence intervals and make inferences about population parameters.
The reference distribution is often derived from the sampling distribution of the statistic being estimated. For example, the sampling distribution of the sample mean is typically normal (or approximately normal, according to the Central Limit Theorem), whereas the sampling distribution of a sample proportion follows a binomial distribution (but can be approximated as normal under certain conditions, which we’ll discuss later in this Lab). Ultimately the specific reference distribution depends on what is being estimated and the assumptions made:
- Normal distribution (Z) is generally used when the population standard deviation is known or for large samples.
- t-distribution is used when the population standard deviation is unknown, especially with small sample sizes.
- Binomial distribution (or normal approximation) is used for proportions, depending on sample size and conditions (discussed in greater detail below).
We can use the flowchart below to identify the most appropriate reference distribution (Z or t) when estimating a population mean:
In most cases, if the population variance is known, we can directly account for variability in the population and use a “reliability coefficient” (Z) from the standard normal distribution, where the formula for the interval estimate of the population mean is as follows:
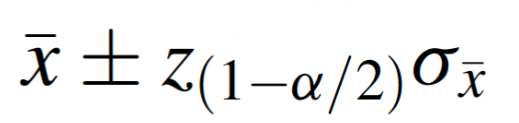
In practice, however, the population variance is rarely known, so we will focus here on the alternative scenario. When the population variance is unknown, we estimate variability using the sample variance and use the t-distribution (rather than the standard normal distribution) in determining the appropriate reliability coefficient. Under these conditions, the formula for the interval estimate of the population mean is as follows:
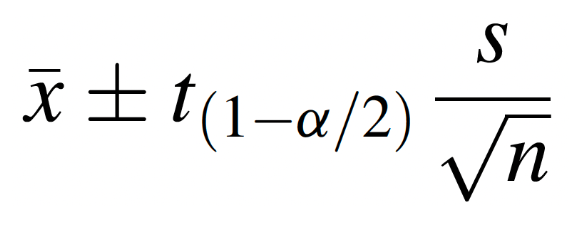
The great thing about using software is that, while we need to make the appropriate analytic decisions and specify a desired level of confidence with which to estimate the population parameter, R handles the calculations for the sample mean, variance, and reliability coefficient, making the process of estimation much more efficient than if we were to carry out these steps by hand.
Back to Framingham… Let’s make the following assumptions:
- BMI is normally distributed in the population.
- We have a large sample.
- Population variance is unknown.
Following the flowchart above, under these conditions we can estimate
the population mean using either the standard normal
distribution (Z) or the
t-distribution. Most often in practice, the
t-distribution will be used (but the results will be very
similar, as the t-distribution approximates the standard normal
distribution with large samples). Let’s take a look at how we can carry
out this task in R using the t.test() function:
##
## One Sample t-test
##
## data: data$BMI
## t = 420.48, df = 4433, p-value < 2.2e-16
## alternative hypothesis: true mean is not equal to 0
## 95 percent confidence interval:
## 25.72565 25.96667
## sample estimates:
## mean of x
## 25.84616First a breakdown of this relatively simple line of code:
t.test(): This function conducts a t-test. By default, it performs a one-sample t-test unless additional arguments are specified (we’ll discuss some of these later).data$BMI: Specifies the variable being tested (in this case,BMI, from the dataset we calleddata).conf.level = 0.95: Sets the confidence level for the interval estimate to 95%.
The output of this function provides several pieces of information, some of which will pertain to hypothesis testing, which we will discuss next week. For now, we are most interested in the confidence interval provided in the output:
- Test Statistic (t): The t-value calculated for the one-sample test.
- Degrees of Freedom (df): The number of observations minus one (n−1).
- p-value: Tests the null hypothesis that the mean of
BMI is equal to 0. Since this is unlikely to be meaningful in practice,
this part of the test is often ignored when using
t.test()primarily for confidence intervals. More on hypothesis testing next week… - Confidence interval: The range of values within which the population mean of BMI is likely to fall, with 95% confidence.
- Sample mean: The mean of BMI in the sample (i.e., the point estimate of the population parameter).
From the output, we find that the mean BMI of the sample is approximately 25.85 (in alignment with the summary statistics we generated previously). The 95% confidence interval for the population mean is (25.72565, 25.96667). This means that we are 95% confident that the true population mean lies within this interval. Notice that the point estimate of the population mean (i.e., the sample mean) falls exactly in the middle of the interval estimate.
6. Estimate the difference between two population means
Next, suppose we want to know whether mean BMI differs by sex assigned at birth − in other words, we want to estimate the difference in population mean BMI between males and females. First, let’s visualize the distribution of BMI by sex assigned at birth in our sample:
# create side-by-side histograms to show the distribution of BMI by sex assigned at birth
data %>%
ggplot(aes(x = BMI, fill = SEX)) +
geom_histogram(color="#e9ecef", alpha=0.5, position = 'identity') +
scale_fill_discrete(labels = c('Males', 'Females')) +
theme_minimal()## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.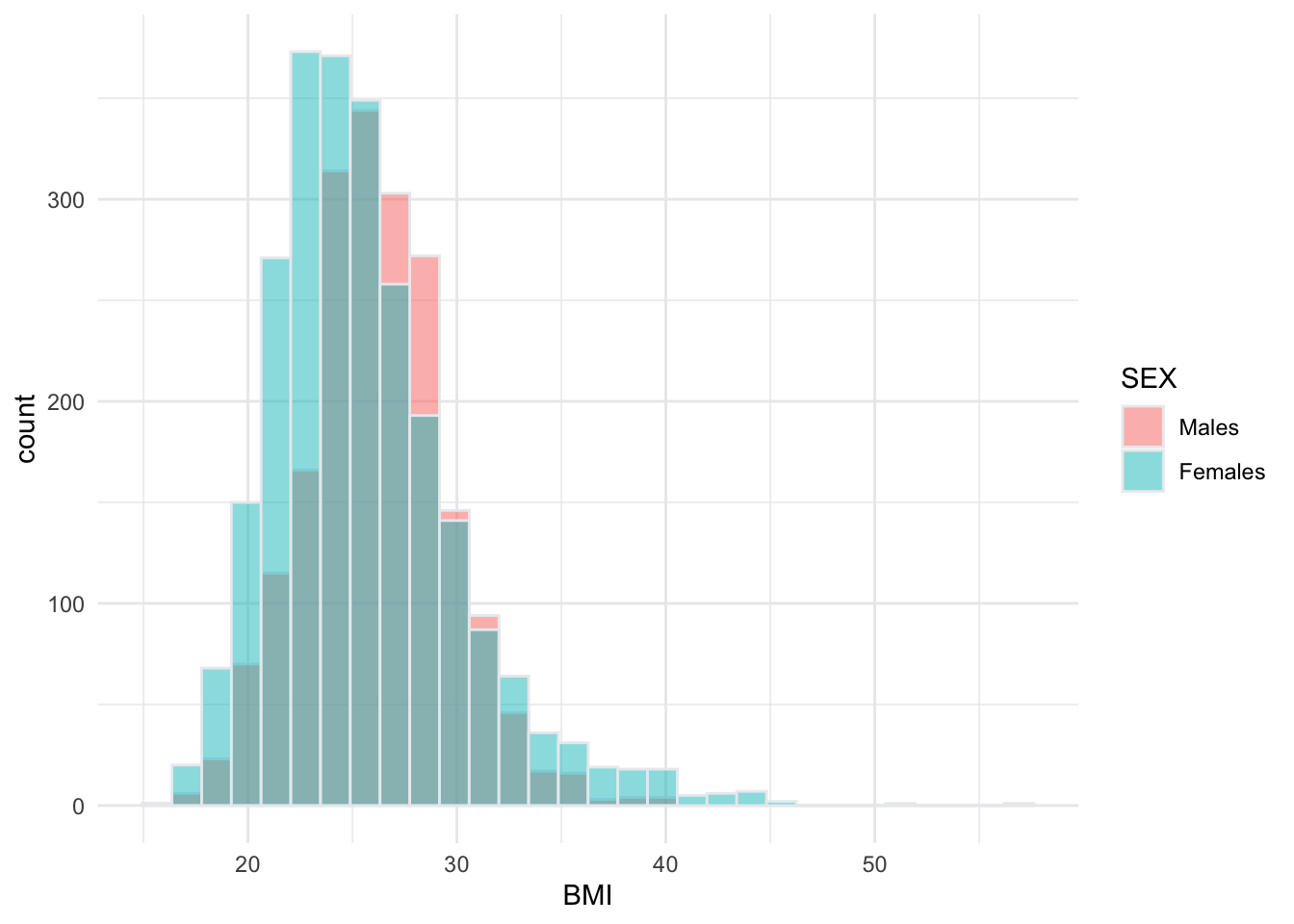
A quick breakdown of this code chunk, in which we are using the
ggplot2 package for the first time(!):
data %>%: The pipe operator (%>%) passes thedataobject as input to theggplot()function.ggplot(aes(x = BMI, fill = SEX)): Initializes the plot using theggplot()function, with the following specifications:aes(x = BMI): Maps theBMIvariable to the x-axis.fill = SEX: Groups the data by theSEXvariable, using different fill colors for each group in the histogram.
geom_histogram(color = "#e9ecef", alpha = 0.5, position = 'identity'):geom_histogram(): Creates the histogram for theBMIvariable.color = "#e9ecef": Adds a light gray border for each bar to help differentiate them.alpha = 0.5: Sets the transparency level, in this case to make the bars semi-transparent so that overlapping sections can be seen.position = 'identity': Ensures the bars for each group are plotted on top of each other, rather than being stacked.
scale_fill_discrete(labels = c('Males', 'Females')): Modifies the legend for the fill colors.labels = c('Males', 'Females'): Replaces the default labels (“1” and “2”) with “Males” and “Females.”
theme_minimal(): Applies thetheme_minimal()styling, which removes gridlines and clutter.
From the histogram we can see that the distributions of BMI among participants with male and female sex assigned at birth overlap substantially. However, the center of the distribution appears to be slightly higher (further to the right) among males than females. Interval estimation of the difference in means will tell us whether this difference is statistically significant, meaning there is a real difference in the population means, unlikely to have occurred by chance.
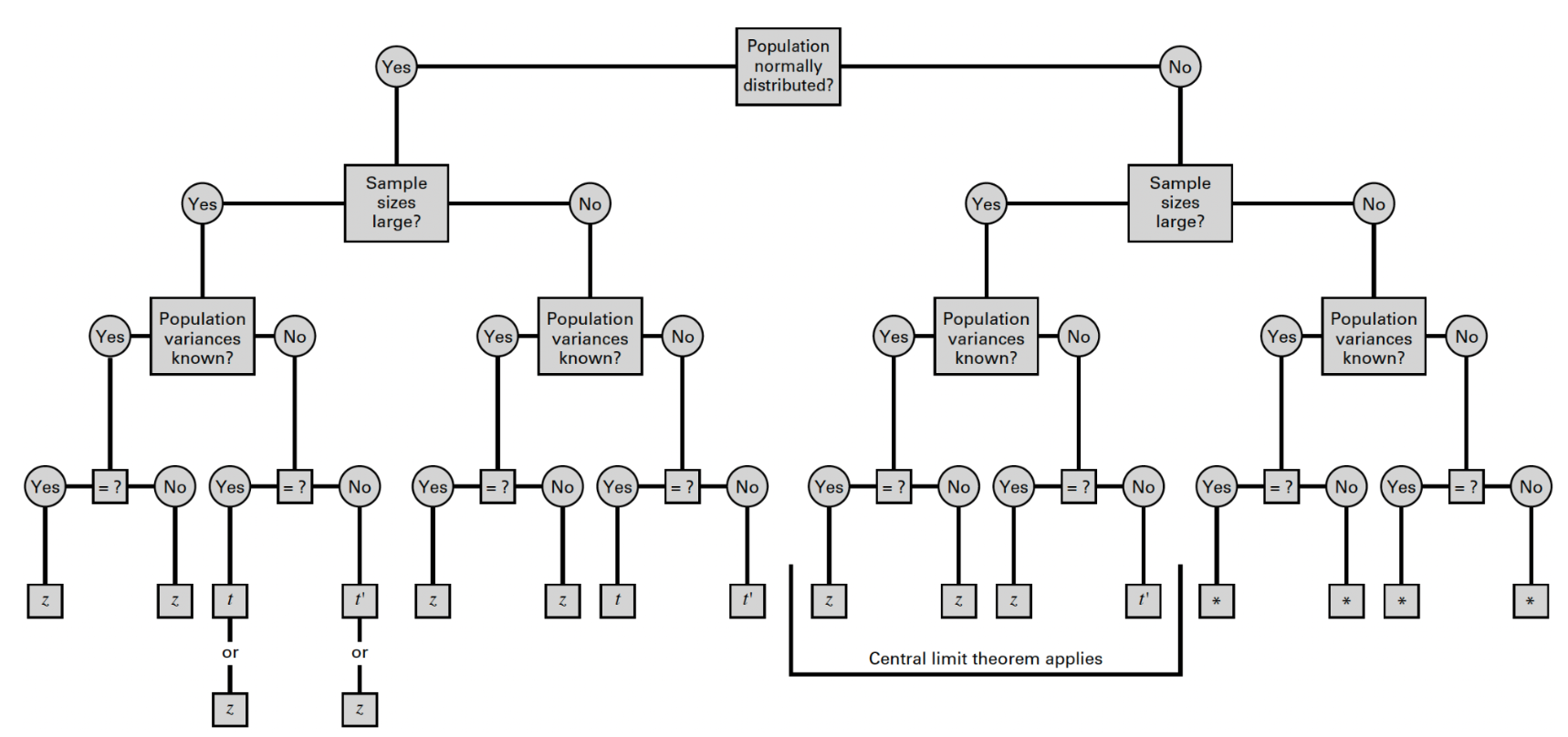
Recall from lecture that the specific approach we use to estimate the difference in population means depends on four conditions:
- Whether or not the populations are normally distributed;
- Whether or not the sample sizes are large;
- Whether or not the population variances are known; and finally,
- Whether or not the population variances are equal.
We can use the flowchart below to identify the most appropriate reference distribution (Z, t, or t’) when estimating the difference in population means:
To estimate the difference in mean BMI between males and females in Framingham, let’s first make the following assumptions:
- BMI is normally distributed in both populations.
- We have large samples.
- Population variances are unknown.
The fourth condition − whether the population variances are equal or not − requires further investigation. There are several approaches for determining whether the population variances are equal or not. In lecture, we discussed one practical approach, in which we can assume the two population variances are unequal if the ratio of the larger variance to the smaller variance exceeds two (or in other words, one variance is more than double the other). However, this approach is not often used in practice as other, more reliable approaches are available. We will focus on two types of statistical tests to determine equality of variances, the F-test and Levene’s test. Since we have not yet discussed statistical tests in detail, these procedures will give a preview to what’s coming next week…
- F-test for equality of variances: Compares the variances of two groups by calculating the ratio of their sample variances. It assumes that the data in each group are normally distributed and tests whether the variances are significantly different. This approach is sensitive to departures from normality, which can affect the validity of the test (in other words, this test is not well suited for skewed data).
- Levene’s test: Compares the variances of two or more groups by assessing the absolute deviations of individual values from their group means or medians. It is less sensitive to departures from normality and is a more robust alternative to the F-test for equality of variances. It is best for most cases where the data are not perfectly normal but not heavily skewed.
Based on the histograms we generated above, we can see BMI by sex assigned at birth is approximately normally distributed but slightly right-skewed. In the future, we will use a statistical test to determine normality, but for now, let’s demonstrate both approaches (F-test and Levene’s test) to determine whether the population variances are equal or not.
F-test for equality of variances
In order to carry out the F-test (using the var.test()
function), we need to first save BMI values for males and females in
separate “vectors” (basically, a list of values) as follows:
# create separate objects containing BMI values for males and females
bmi_male <- data$BMI[data$SEX == "1"]
bmi_female <- data$BMI[data$SEX == "2"]After running the above code chunk, you should see two new objects in
your Environment, bmi_male and bmi_female,
under “Values”. We can now use these objects in the
var.test() function as follows:
# Apply F-test for equality of variances to vectors containing male and female BMI values
var.test(bmi_male, bmi_female)##
## F test to compare two variances
##
## data: bmi_male and bmi_female
## F = 0.56061, num df = 1943, denom df = 2489, p-value < 2.2e-16
## alternative hypothesis: true ratio of variances is not equal to 1
## 95 percent confidence interval:
## 0.5155947 0.6098333
## sample estimates:
## ratio of variances
## 0.5606144When running the F-test, we really only need to pay attention to one component of the output − the p-value. When the p-value is small (for now, let’s consider “small” to be less than 0.05), we can conclude that the population variances are not equal, as is the case here for BMI values among males and females.
Note: When a value is very small, R will often put the value in scientific notation. For example, we see the p-value in the above output is shown as 2.2e-16. This is scientific notation for 0.00000000000000022 (so, almost zero). R uses this notation automatically for very small numbers. Keep this in mind as your interpret p-values (which you’ll be doing a lot!) moving forward.
Levene’s test for equality of variances
Let’s next use Levene’s test for equality of variances. Given our
data are slightly skewed, Levene’s Test is the more appropriate option
in this case. For this test we will use the leveneTest()
function from the car package as follows:
## Levene's Test for Homogeneity of Variance (center = median)
## Df F value Pr(>F)
## group 1 72.717 < 2.2e-16 ***
## 4432
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1A quick breakdown of the code:
leveneTest(): Levene’s test checks whether the variances of a continuous variable (e.g., BMI) are the same across two or more groups (in this case, sex assigned at birth).BMI ~ SEX: The formula specifies the relationship being tested.BMIis the dependent variable whose variances are being compared.SEXis the grouping variable (independent variable), which divides the data into groups (e.g., males and females).
data = data: Specifies the data object we are using (calleddata), which contains the variablesBMIandSEX.
Fligner-Killeen’s test (an alternative to Levene’s test)
If you have trouble installing the car package, the
following test − called the Fligner-Killeen’s test − can be used as an
alternative to Levene’s test. This test is from the stats
package which you should already have installed.
##
## Fligner-Killeen test of homogeneity of variances
##
## data: BMI by SEX
## Fligner-Killeen:med chi-squared = 60.619, df = 1, p-value = 6.927e-15Whether you used Levene’s test or Fligner-Killeen’s test, like the output from the F-test, we are most concerned with the p-value. A small p-value (less than 0.05), as we see in this case, indicates the difference in variances is statistically significant.
We now have two statistical tests − the F-test and Levene’s test (or Fligner-Killeen’s test) − that suggest the variances in BMI for males and females are not equal. Given this information, we will proceed with estimating the difference in population means using Welch’s t-test (applying the t’ reference distribution), which uses the following formula:
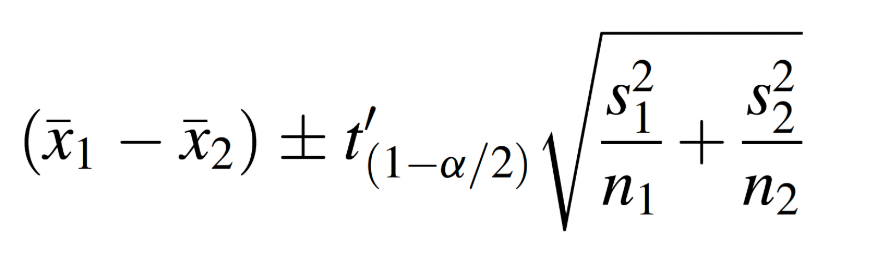
To do this in R, we will carry out a two-sample t-test with
unequal variances using the t.test() function as
follows:
# calculate 95% confidence interval for difference in mean BMI by sex assigned at birth
t.test(BMI ~ SEX, data = data, var.equal = FALSE, conf.level = 0.95)##
## Welch Two Sample t-test
##
## data: BMI by SEX
## t = 4.812, df = 4424.5, p-value = 1.544e-06
## alternative hypothesis: true difference in means between group 1 and group 2 is not equal to 0
## 95 percent confidence interval:
## 0.3404038 0.8084815
## sample estimates:
## mean in group 1 mean in group 2
## 26.16875 25.59431Let’s break down this code:
t.test(): The function in R that conducts a t-test. In this case, it performs a two-sample t-test because the response variable (BMI) is compared across two groups defined by the explanatory variable (SEX).BMI ~ SEX: The formula specifies the dependent variable (BMI) and the grouping variable (SEX). This indicates that the means of BMI will be compared between the two levels of SEX (e.g., “Male” and “Female”).data = data: Specifies the dataset (data) containing the variablesBMIandSEX.var.equal = FALSE: Indicates that the two groups are assumed to have unequal variances (Welch’s t-test). Welch’s t-test is more robust than a regular t-test when the variances of the two groups are unequal. If we setvar.equal = TRUE, the variances are assumed to be equal across groups and a pooled variance approach is used instead.conf.level = 0.95: Sets the confidence level for the confidence interval to 95%.
From the output, we see the mean BMI among males and females in the sample were 26.16875 and 25.59431, respectively. The 95% confidence interval for the difference in means is (0.3404038, 0.8084815). When estimating a difference in means, the first thing to look for is whether the interval estimate contains zero. If zero is within the interval (i.e., the lower bound is a negative value and the upper bound is a positive value), this means we do not have enough evidence to conclude there is a statistically significant difference in population means. For our scenario here, the output shows a confidence interval with positive lower and upper bounds, indicating the population means are different, with 95% confidence, by an amount within the interval estimate (again, 0.3404038 to 0.8084815).
From the flowchart above, we can see that either the Z or t’ reference distribution would be appropriate for our specific scenario. Just for practice, suppose we wanted to try this problem using a z-test, which would use the following formula:
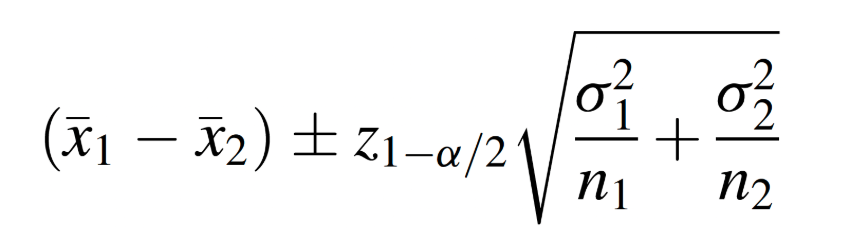
To do this in R, we need to use the objects we created previously
which contained BMI values for males and females separately. We would
additionally need to create objects for the values of the sample
standard deviations using the sd() function as follows:
# obtain sample standard deviations for BMI among males and females
sd_m <- sd(bmi_male, na.rm = TRUE)
sd_f <- sd(bmi_female, na.rm = TRUE)Now that we have separate R objects containing the list of BMI values
for males and females, and objects for the standard deviation of each
group, we can apply the z.test() function from the
BSDA package as follows:
# Run z.test to obtain 95% confidence interval for difference in means
z.test(bmi_male, bmi_female, mu = 0, sigma.x = sd_m, sigma.y = sd_f, conf.level = 0.95)##
## Two-sample z-Test
##
## data: bmi_male and bmi_female
## z = 4.812, p-value = 1.494e-06
## alternative hypothesis: true difference in means is not equal to 0
## 95 percent confidence interval:
## 0.3404678 0.8084175
## sample estimates:
## mean of x mean of y
## 26.16875 25.59431First a breakdown of this code:
z.test(): This function performs a z-test to compare population means.bmi_maleandbmi_female: These are the two vectors containing BMI values for males and females, respectively.mu = 0: The hypothesized difference in population means is equal to 0. This is the default assumption unless otherwise specified. More on hypothesis testing next week…sigma.x = sd_mandsigma.y = sd_f:sigma.x = sd_m: The standard deviation of BMI among males in the sample.sigma.y = sd_f: The standard deviation of BMI among females in the sample.
conf.level = 0.95: Sets the confidence level for the confidence interval of the mean difference to 95%. A 95% confidence level means that the true difference in population means is expected to fall within the interval 95% of the time.
Using this procedure, we find that the mean BMI values among males and females in the sample are 26.16875 and 25.59431, respectively (expectedly, the same result as before). And we find that the 95% confidence interval for the difference in means is (0.3404678, 0.8084175). This result is almost exactly the same as our original estimate using Welch’s t-test. In alignment with our previous findings, this result provides evidence that, with 95% confidence, the population means are different by an amount within the interval estimate.
Again, while both the Welch’s t-test and z-test procedures may have been appropriate here under the given conditions, you will most often see the t-test approach used in practice.
7. Estimate a population proportion
Suppose we want to use the Framingham Heart Study baseline sample to estimate obesity prevalence among the adult population of the city of Framingham. In other words, we want to estimate the proportion of the adult population who are obese (defined as BMI>30). The formula to estimate a population proportion is as follows:
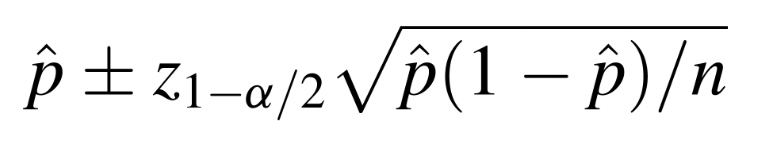
To do this in R, we first need to know how many people there are in the sample with obesity as well as the total sample size:
##
## 0 1
## 3860 574From the output, we see there are 574 individuals with obesity (BMI>30) in the sample, out of a total sample of 4,434.
We can calculate the 95% confidence interval for the population
proportion using the prop.test() function as follows:
# Calculate 95% confidence interval for proportion obese in Framingham
prop.test(574, 4434, conf.level = 0.95, correct = FALSE)##
## 1-sample proportions test without continuity correction
##
## data: 574 out of 4434, null probability 0.5
## X-squared = 2435.2, df = 1, p-value < 2.2e-16
## alternative hypothesis: true p is not equal to 0.5
## 95 percent confidence interval:
## 0.119893 0.139657
## sample estimates:
## p
## 0.1294542A breakdown of this line of code:
prop.test(): This function tests hypotheses about proportions and provides a confidence interval for the population proportion.574: The number of “successes” or events of interest (x) in the sample. In this context, it represents the number of individuals classified as obese.4434: The total number of “trials” or observations (n) in the sample. Here, it represents the total sample size.conf.level = 0.95: The confidence level for the confidence interval around the estimated proportion. A 95% confidence level means the true population proportion is expected to lie within the interval 95% of the time.correct = FALSE: Disables the Yates’ continuity correction, which is often applied to adjust for small sample sizes or prevent overestimation of significance.
From the output, we see a point estimate of obesity prevalence (i.e., the sample proportion) is 0.1294542 (about 12.95%), and the 95% confidence interval for obesity prevalence is (0.119893, 0.139657), or about 11.99% to 13.97%. This means that we are 95% confidence that the true obesity prevalence (i.e., the population proportion) falls within this interval.
8. Estimate the difference between two population proportions
Finally, suppose we want to know whether there is a difference in obesity prevalence by sex assigned at birth. Recall from Lab 2 that we visualized the relative frequencies of obesity among males and females in the sample using a side-by-side bar chart as follows:
# Create the contingency table
contingency_table <- table(data$SEX, data$OBESE)
# Calculate relative frequencies using the `prop.table()` command
relative_frequencies <- prop.table(contingency_table, margin = 1)
# Print relative frequencies
print(relative_frequencies)##
## 0 1
## 1 0.8806584 0.1193416
## 2 0.8626506 0.1373494# Bar chart for relative frequencies
barplot(relative_frequencies,
beside = TRUE,
main = "Obesity Prevalence by Sex Assigned at Birth",
xlab = "Obesity Status",
ylab = "Proportion",
col = c("lightblue", "lightgreen"),
legend = c("Male", "Female"),
names.arg = c("Not Obese", "Obese"))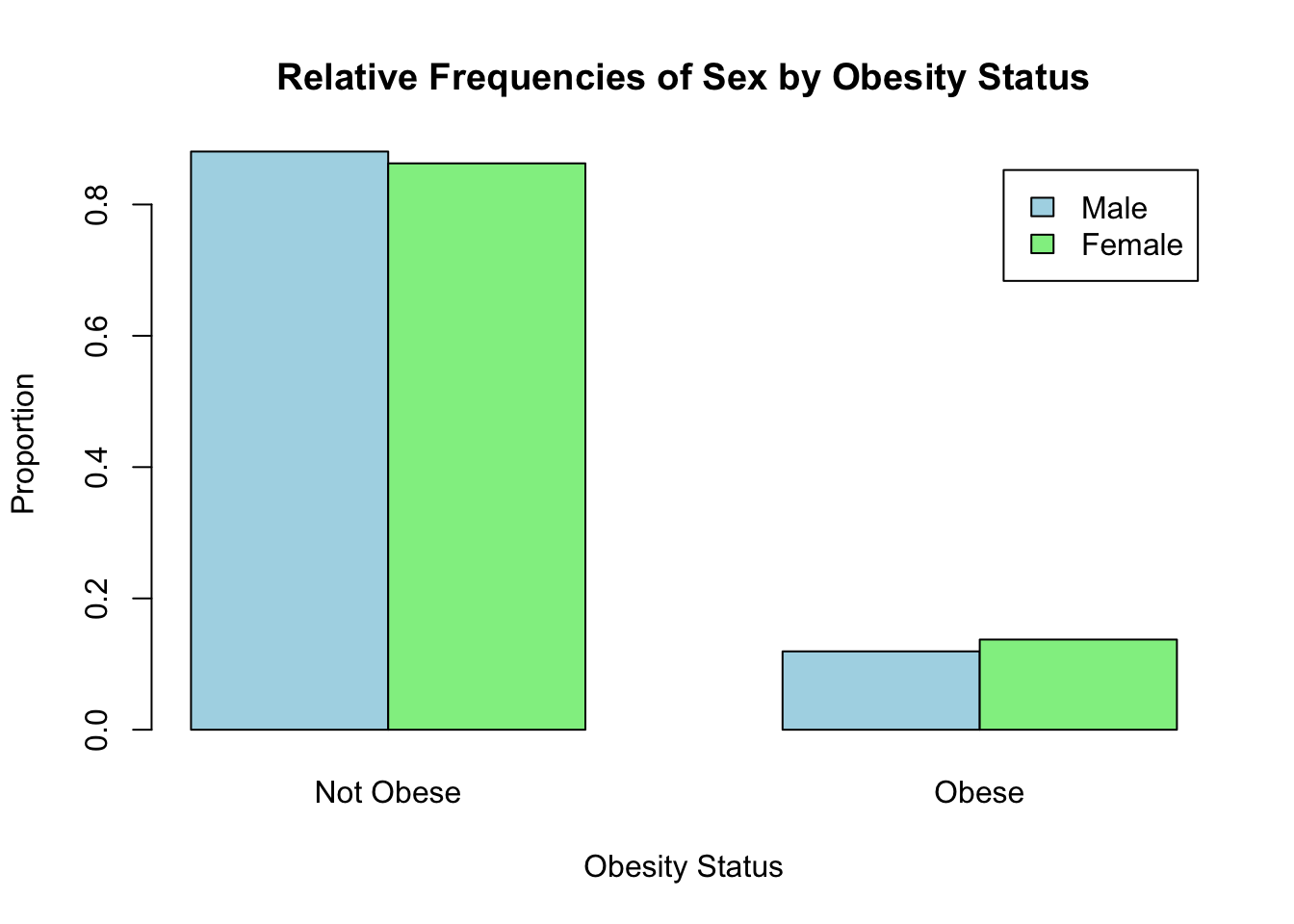
From the bar chart, it appears obesity prevalence is slightly higher among females than males. But is the difference statistically significant? In other words, based on our sample data, do we have enough evidence to conclude that obesity is more prevalent among females in the population than among males? The formula to estimate the difference in population proportions is as follows:
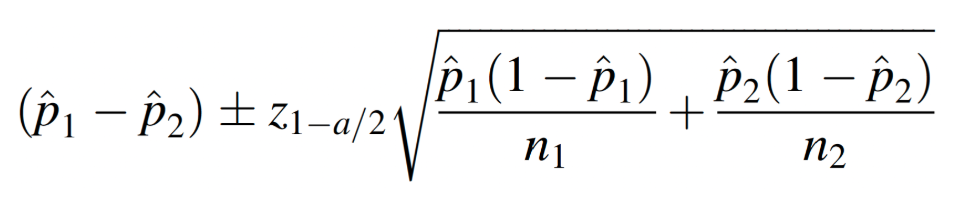
To do this in R, we first need to know the number of individuals in the sample with obesity, stratified by sex assigned at birth. We also need the total number of males and females in the sample. We can obtain these values using the ‘table’ command as follows:
# generate counts of obesity by sex and totals by sex
table(data$SEX, data$OBESE) # counts of obesity by sex##
## 0 1
## 1 1712 232
## 2 2148 342##
## 1 2
## 1944 2490The code chunks above generate two tables in the Console window. The
first provides a count of individuals with obesity by sex assigned at
birth, and the second provides the totals by sex. From the first table,
we see there are 232 males with obesity, and there are 342 females with
obesity. From the second table, we see there are a total of 1,944 males
in the sample and 2,490 females. Next, we will use these values to
estimate the difference in population proportions using the
prop.test() function as follows:
# obtain 95% confidence interval for difference in obesity prevalence by sex
prop.test(c(232, 342), c(1944, 2490), conf.level = 0.95, correct = FALSE)##
## 2-sample test for equality of proportions without continuity correction
##
## data: c(232, 342) out of c(1944, 2490)
## X-squared = 3.1413, df = 1, p-value = 0.07633
## alternative hypothesis: two.sided
## 95 percent confidence interval:
## -0.037768267 0.001752599
## sample estimates:
## prop 1 prop 2
## 0.1193416 0.1373494First a breakdown of this line of code:
prop.test(): Function used to compare proportions between two or more groups.c(232, 342): A vector containing the counts of “successes” (e.g., individuals with obesity) in each group:232: Number of males with obesity (X1).342: Number of females with obesity (X2).
c(1944, 2490): A vector containing the total number of observations (sample size) in each group:1944: Total number of males in the sample (n1).2490: Total number of females in the sample (n2).
conf.level = 0.95: Specifies the confidence level for the confidence interval around the difference in proportions. Here, it is set to 95%.correct = FALSE: Disables the Yates’ continuity correction, which is often applied to adjust for small sample sizes or prevent overestimation of significance.
The output here contains several pieces of information (but, as before, we are most interested for now in the confidence interval):
- Chi-Square test statistic (“X-squared”): A test statistic that evaluates whether the difference in proportions is statistically significant. (More on this later in the course…)
- Degrees of freedom (df): The degrees of freedom for the test (usually 1 for a two-sample test).
- p-value: Indicates whether the observed difference in proportions is statistically significant. A small p-value (<0.05) suggests a significant difference between the proportions. More next week…
- Confidence interval (95% by default): Provides a range of values within which the true difference in population proportions is likely to fall.
- Sample estimates: Displays the sample proportions for each group (e.g., the proportion of obese individuals in males and females).
From the output, we are most interested (again, for now) in the confidence interval for the difference in proportions. We can use the confidence interval to determine whether there is a statistically significant difference between groups, and if so, how much that difference is estimated to be. When estimating a difference in population proportions − just as when estimating a difference in population means − the first thing to look for is whether zero (0) is contained within the interval. If zero is within the confidence interval (in other words, if the lower bound is a negative value and the upper bound is a positive value), this means we do not have enough evidence to conclude there is a difference between groups.
For the current scenario, we see the difference in population proportions is estimated to be (-0.037768267, 0.001752599). As zero is within this interval, we do not have enough evidence to conclude there is a difference in obesity prevalence between males and females in Framingham.
Summary
In Lab 4, we’ve taken the next step in building statistical inference skills by focusing on estimation. You’ve learned how to calculate and interpret point estimates and confidence intervals for a population mean, the difference between two means, a population proportion, and the difference between two proportions. These estimation procedures rely on important assumptions: the “target population” (the population we want to study) and the “sampled population” (the population from which our sample is drawn) must be the same. If these populations differ in any way, this needs to be accounted for when interpreting results. Additionally, we assume that samples are drawn using probability sampling techniques, such as random sampling, to ensure that the results are representative and unbiased. With these tools and assumptions in mind, we’re ready to move forward into our next topics like hypothesis testing and regression analysis.
When you are ready, please submit the following to the Lab 4 assignment page on Canvas:
- An R Markdown document, which has a
.Rmdextension - A knitted
.htmlfile
Please reach out to me at jenny.wagner@csus.edu if you have any questions. See you in class!
Jenny Wagner, PhD, MPH
Assistant Professor
Department of Public Health
California State
University, Sacramento
jenny.wagner@csus.edu